Introduction to Pandas in Python: Uses, Features & Benefits
Pandas is a valuable open-source library for Python, designed to streamline data science and machine learning tasks. It provides core structures and functions to simplify the process of manipulating and analyzing data.
Pandas in Python is an essential tool for analysts and developers in every field from economics and DSP advertising to neuroscience and NLP. This article covers a brief introduction to Python Pandas, how it works, its applications, and its benefits—enjoy!
What is Pandas for Python?
"Pandas" is a contraction of the words "Panel" and "Data," but it is also a contraction of the term "Python Data Analysis."
Panel Data is a form of multidimensional data that logs the behaviors of multiple subjects over multiple time periods or points in time.
Python Data Analysis is basically any form of analysis that's being streamlined by Python-based tools.
So, the name says a lot about Pandas' function, which is to make quick work of messy data, clarifying and organizing it for relevance, and deleting NULL values as needed.
Python Pandas library provides two primary data structures, DataFrame and Series. These streamline the processes of tabular data management for both textual and numerical data, including:
data loading
data tabulating
data cleaning
data filling
NULL data deletion
data normalization
data inspection
statistical data analysis
data saving, and more.
Pandas allows for efficient and flexible numerical data and textual data handling and, when you combine Pandas module with other, complementary Python modules, it streamlines all aspects of data cleaning, manipulation, and analysis.
How to import Pandas in Python?
1. Installing Anaconda to get Python and Pandas
Installing Pandas is simple, even if you haven't got Python installed yet. To add Python to your operating system—and install Pandas and hundreds of other scientific Python packages in the process—just install Anaconda.
Anaconda is a powerful Python distribution that's made for all breeds of data scientists. Once you install Anaconda, you won't have to worry about software compilations or going through any of the usual steps to get Pandas installed and running.
To download and install Anaconda for Mac, Windows or Linux, go here: https://www.anaconda.com.
2. Installing Pandas via Python and Pip package manager
Alternatively, install Pandas by importing it straight into Python using PIP package manager. There's no need to install PIP even when using VPN, as it installs automatically with Python.
You can install Python by visiting their official website: https://www.python.org/downloads/ and, once you've installed Python, use the PIP package manager to install Pandas library.
To install Pandas, just open a Command Prompt and type:
pip install Pandas
After installing Pandas, import the library to your Python script or notebook by entering the following Command Prompt:
import Pandas as pd
How does Pandas work?
Pandas revolves around the concept of the DataFrame and Series objects. DataFrames are two-dimensional tables that can store data in rows and columns, while Series objects are one-dimensional arrays that store only data of a single type.
Pandas sits astride the NumPy library, which supports efficient numerical operations on large arrays. This integration with NumPy allows seamless and fast operations between the two libraries, one tabular and one numerical.
DataFrame and Series objects can be created from various data sources, such as CSV files, Excel files, SQL databases, or even Python dictionaries and lists.
Once you install Pandas, you'll have access to several functions for reading and writing data from diverse sources, streamlining your data tabulation process, no matter the format.
The key features of Python Pandas
With Pandas module up and running, you can import your data into a DataFrame or Series and use Pandas' extensive functionality to manipulate, clean, and analyze that data. Key features and functions of Pandas include:
1. Data cleaning
Pandas offers various functions for cleaning and transforming your data, such as filling in missing values, dropping columns or rows, deleting NULL values and renaming columns.
2. Data filtering and selection
Pandas allow for a range of fine filtering and selection functions, based on highly granular conditions. So, no matter how complex the data is, you can extract the exact information you want.
3. Data aggregation
With Pandas, you can perform aggregation operations like groupby, pivot, and merge to summarize and restructure your data.
4. Data visualization
Pandas integrates with the popular data visualization library, Matplotlib, allowing you to create various types of plots and charts from your data.
The benefits of learning Pandas library
Why should you use Pandas? There are several reasons to use Pandas for data analysis and manipulation, including but not limited to:
1. Efficient data handling
Pandas provides a functional framework for handling large datasets with ease. The library is built on top of NumPy, which ensures fast and efficient numerical operations.
2. Flexibility
Pandas offers an arsenal of functions and methods for data manipulation, and it's a flexible tool for all sorts of data scientist and manager tasks.
3. Easy integration with other libraries
Pandas integrates seamlessly with popular Python libraries like NumPy, SciPy, and Matplotlib, creating powerful pipelines for data analytics.
4. Wide adoption and support
Pandas is widely used in the data science community, so you'll find ample resources, tutorials, and support through online forums.
5. Readability
The Pandas package has a clear and concise syntax, so it's easy to read and understand. This readability makes your code easier to append and maintain, driving smooth collaboration with others and longevity for your projects.
6. Handling diverse data sources
Once you install Pandas and start importing data from diverse sources, Pandas lets you efficiently process that data.
This includes reading and writing data sources such as CSV files, Excel files, and SQL databases. This versatility makes Pandas libraries a popular solution through a range of fields, where data comes in diverse sets and formats.
The applications of Pandas in Python
What are the use cases for Pandas? Pandas is used across a range of data science and management fields, thanks to its army of applications:
1. Data cleaning and preprocessing
Pandas is an excellent tool for cleaning and preprocessing data. It offers various functions for handling missing values, transforming data, and reshaping data structures.
2. Data exploration
Pandas makes it easy to explore and understand your data. You can quickly calculate summary and basic statistics, filter multiple rows or tables, and visualize data using Pandas' integration with Matplotlib.
3. Feature engineering
Pandas provides robust functionality for creating new features from existing data, such as calculating aggregate statistics, creating dummy variables, and applying custom functions.
4. Time series analysis
Pandas has built-in support for handling time series data, streamlining work with time-stamped data, resampling operations, and rolling statistics calculations.
5. Data science
Pandas plays a crucial role in preparing data for machine learning models. By cleaning, preprocessing, and transforming data with Pandas, you can create structured datasets that can be used with machine learning libraries like scikit-learn or TensorFlow.
What are examples of Pandas operations?
Here are some common examples of tasks you can master once you install Pandas:
1. Load data from a CSV file
This code imports the Pandas library and reads a CSV file called "data.csv." The data sets from the CSV file are loaded into a DataFrame object called df.
DataFrames are the primary data structure used in Pandas for storing and manipulating data. Open a command prompt and enter:
import Pandas as pd
df = pd.read_csv("data.csv")
2. Selecting specific columns
This code selects two specific columns, "column1" and "column2". from the DataFrame df and creates a new DataFrame called selected_columns, containing only those columns.
selected_columns = df[["column1","column2"]]
3. Filtering rows based on a condition
This code filters the DataFrame df to include only rows where the value in "column1" is greater than 10.
The filtered rows are stored in a new DataFrame called filtered_rows.
filtered_rows = df[df["column1"]>10]
4. Renaming columns
This code renames a column in the DataFrame df by providing a dictionary with the old column name as the key and the new column name as the value.
The inplace=True argument tells Pandas to perform the renaming operation directly on the original DataFrame, rather than creating a new DataFrame with the updated column names.
Enter the following command:
df.rename(columns={"old_column_name":"new_column_name"}, inplace=True)
5. Grouping data by a specific column
This code groups the DataFrame df by the unique values in the "column1" column and calculates the mean of the other columns for each group.
The resulting grouped data is stored in a new DataFrame called grouped_data.
grouped_data=df.groupby("column1").mean()
6. Merging two DataFrames
This code merges two DataFrames, df1 and df2, based on a common column called "common_column".
The resulting merged DataFrame is stored in a new DataFrame called merged_data.
merged_data=pd.merge(df1,df2,on="common_column")
7. Creating a line plot with Pandas and Matplotlib
This code imports the Matplotlib library and uses the built-in Pandas plotting function to create a line plot.
The x-axis represents the data in the "column1" column, and the y-axis represents the data in the "column2" column.
The kind="line" argument specifies that the plot should be a line plot. Finally, plt.show() displays the plot.
Enter the following command:
import matplotlib.pyplot as plt
df.plot(x="column1",y="column2",kind="line")
plt.show()
These examples showcase just a small portion of the vast functionality of Pandas for Python. We recommend reviewing the official Pandas documentation at: https://Pandas.pydata.org/Pandas-docs/stable/index.html) and exploring online tutorials to discover even more operations and use cases.
Conclusion
Pandas is a powerful and versatile Python analysis library. With its efficient data structures, extensive functionality, and integration with other popular Python libraries, Pandas has become an essential tool for data scientists, analysts, engineers and developers.
Whether cleaning data, exploring relationships between variables, or preparing data for machine learning models, Pandas provides a comprehensive and efficient solution for all your data processing needs.
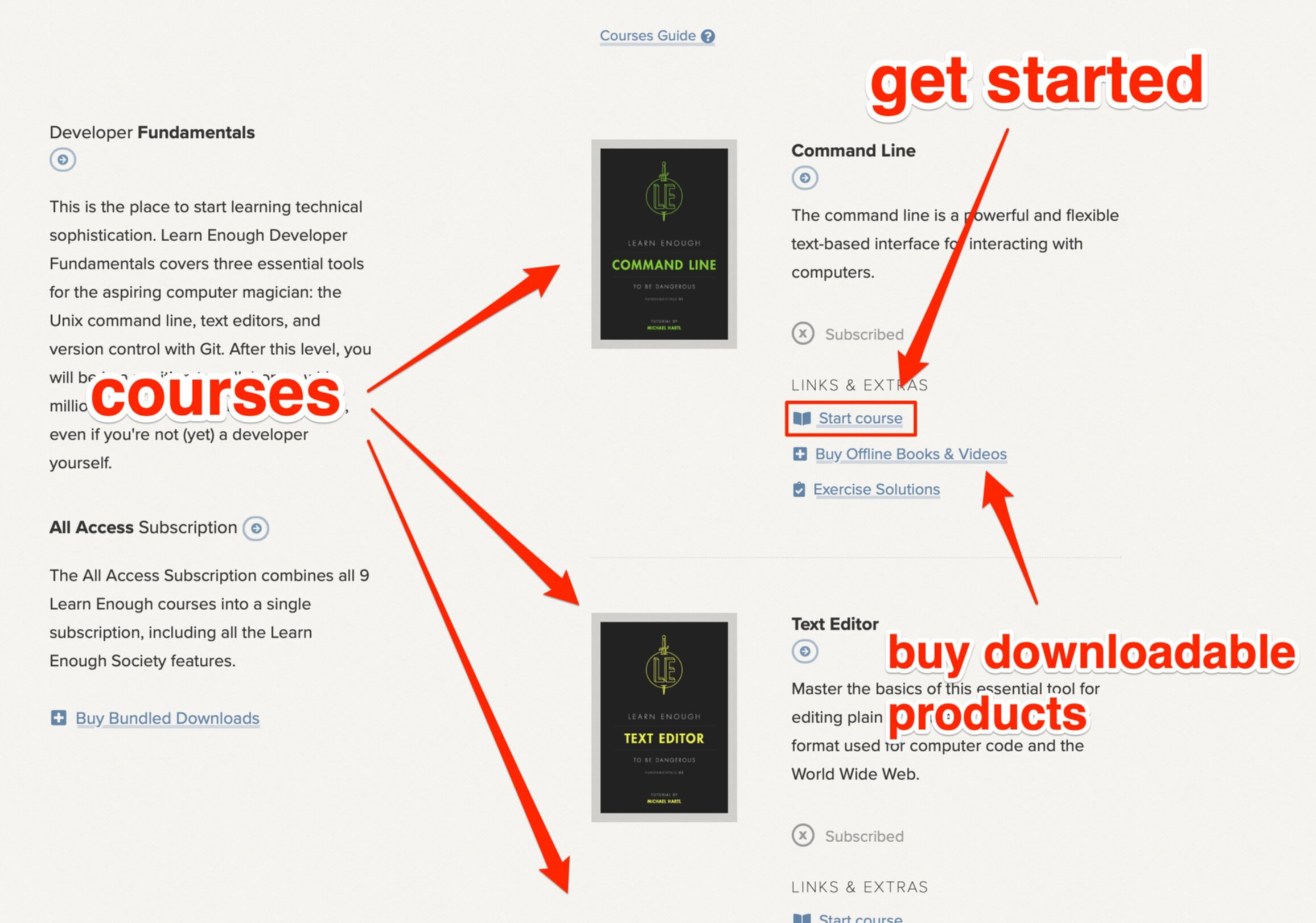
As an aspiring Python dev or data specialist, you’re probably wondering where the heck to start. We recommend “Learn Enough Python To Be Dangerous,” a comprehensive 450-page all-in beginners course with 9 hours of embedded videos and over 100 empowering Python exercises.
About Learn Enough
At Learn Enough, we provide carefully designed courses to take you from a beginner to a professional-grade analyst or developer.
Every Learn Enough All Access subscription includes Learn Enough Python To Be Dangerous, our leading introduction to Python applications, analysis and development.
If you manage a team of analysts and developers, Learn Enough for Teams boosts the skills of your juniors and gets your seniors quickly up to speed with the latest versions of Python, Ruby on Rails, and more.
Start your all-access 7-day free trial today!

All Access Subscription
Get free access to all 10 Learn Enough courses (including the Ruby on Rails Tutorial) for 7 days!
Free 7 Day trial details
We require a credit card for security purposes, but it will not be charged during the trial period. After 7 days, you will be enrolled automatically in the monthly All Access subscription.
BUT you can cancel any time and still get the rest of the 7 days for free!
All Learn Enough tutorials come with a 60-day 100% money-back guarantee.